

1. Introducción
Si conoces llama.cpp, motor de inferencia para cargar modelos LLM para generar texto, es fácil entender que es lo que hace stablediffusion.cpp, ya que es su equivalente para generar imágenes.
Se trata de un software que permite conectar un modelo de difusión para generar imágenes con la tarjeta gráfica del sistema, permitiendo crear imágenes en base a una entrada de datos que puede ser texto, imágenes o a veces incluso hasta video.
2. Instalación
Tras realizar la instalación de drivers, idéntica a la instalación de drivers de llama.cpp, de forma muy similar necesitaremos elegir el backend que vamos a utilizar dependiendo de nuestro sistema operativo y tarjeta gráfica:
| Backend | Rendimiento | Nvidia | AMD | Observaciones |
|---|---|---|---|---|
| CUDA (Nvidia) | 🟩🟩🟩🟩🟩 | ✅ | ❌ | |
| ROCm/HIP (AMD) | 🟩🟩🟩🟩🟩 | ❌ | ✅ | |
| Vulkan | 🟩🟩🟩🟩⬛ | ✅ | ✅ | |
| CPU/RAM | 🟨🟨⬛⬛⬛ | ❌ | ❌ | Opción ideal para sistemas sin GPU (o poco potentes). |
Lo primero será acceder a la página de descargas de Stable Diffusion releases en Github. Una vez ahí tenemos que decidir el backend mediante cuál vamos a conectar:
-
Si tienes Windows, descarga los ficheros
sd-master-*-bin-win-cuda12-x64.zipycudaart-sd-bin-win-cu12-x64.zip. Descomprime ambos en una carpeta, por ejemploc:\sd.cpp. -
Si tienes Linux, tendrás que descargar el fichero
source codey seguir sus instrucciones para compilarlo.
Observa que en cualquiera de los dos casos, si tienes algún tipo de problema, puedes probar como alternativa usar Vulkan.
-
Si tienes Windows, descarga el fichero
sd-master-*-bin-win-rocm-*-x64.zip. Descomprime su contenido en una carpeta, por ejemploc:\sd.cpp. -
Si tienes Linux, descarga el fichero
sd-master-*-bin-Linux-Ubuntu-*-x86_64-rocm-*.zip. Descomprime su contenido en una carpeta, por ejemplo/opt/sd.cpp.
Si tienes algún tipo de problema, puedes probar Vulkan como alternativa.
Vulkan es la opción más sencilla para cualquier tipo de sistema, ya que soporta cualquier tipo de gráfica, tanto en Windows como en Linux.
-
Si estás en Windows, descarga el fichero
sd-master-*-bin-win-vulkan-x64.zip. Descomprime su contenido en una carpeta, por ejemploc:\sd.cpp. -
Si estás en Linux, descarga el fichero
sd-master-*-bin-Linux-Ubuntu-*-x86_64-vulkan.zip. Descomprime su contenido en una carpeta, por ejemplo/opt/sd.cpp.
Si tienes una tarjeta gráfica integrada, o una poco potente, puedes probar a utilizar la CPU para hacer inferencia.
-
Si estás en Windows, te aconsejo descargar el software cpu-z. En la sección
Instructionsdebes mirar a ver cuál aparece:avx,avx2,avx512o ninguna, ya que necesitarás ese dato para saber cuál descargar. Una vez lo sepas, descarga el ficherosd-master-*-bin-win-*-x64.zipcorrespondiente para esa versión y descomprimelo en una carpeta comoc:\sd.cpp. -
Si tienes Linux, descarga el fichero
sd-master-*-bin-Linux-Ubuntu-*-x86_64.zip. Descomprime su contenido en una carpeta, por ejemplo/opt/sd.cpp.
3. Descarga del modelo
Para hacer una prueba vamos a utilizar un modelo de SDXL, ya que son sencillos, ofrecen muy buena calidad, no son demasiado pesados y son relativamente rápidos para hacer inferencia.
Vamos a descargarnos, por ejemplo, el modelo Juggernaut XL ~7GB, un archivo con extensión .safetensors que contiene tres partes importantes: el Modelo de difusión (el dibujante), el CLIP (el que traduce tu prompt) y el VAE (el compresor/decompresor). En SDXL estos tres componentes vienen juntos en un mismo archivo, otros sistemas como Qwen Image, Z-Image u otros son más complejos ya que son archivos por separado. Lo descargamos en la carpeta de sd.cpp.
Recuerda que
stable-diffusion.cppsoporta casi todo tipo de modelos de generación de imagen. Hemos usadoSDXLpor simplicidad, pero también podemos usar otros comoQwen Image,FLUX,Z-Image,Anima,Lensy muchos otros, incluso modelos de generación de video comoWANoLTX.
4. Uso
StableDiffusion.cpp tiene dos ficheros binarios ejecutables. Uno, sd-cli para pruebas o lanzar generaciones individuales, y otro sd-server para lanzar un servidor al cuál puedes conectar vía API y añadir peticiones de generación de imágenes. Aunque más adelante utilizaremos sd-server, vamos a empezar con sd-cli para comprender el funcionamiento.
Para hacer nuestra primera prueba, abriremos una terminal en la carpeta de sd.cpp y escribimos el siguiente comando:
sd-cli -m juggernautXL_ragnarokBy.safetensors \
-W 800 -H 600 \
--clip-on-cpu \
--seed -1 \
--cfg-scale 3.0 --sampling-method euler \
-p "cyberpunk male cat, cyberpunk city, neon lights, volumetric lights, night, yellow eyes, red leather jacket, black hair, soft cinematic lighting, ultra detailed" \
-o image.png
En este pequeño ejemplo con -m seleccionamos el modelo a utilizar, establecemos una imagen de 800x600, con --clip-on-cpu obligamos a que use el traductor en CPU (y ahorrar un poco de VRAM), con --seed -1 establecemos una semilla aleatoria (sin esto, si el prompt no cambia, la imagen generada siempre será la misma) y establecemos un CFG de 3.0 con el sampling Euler (más adelante veremos estos parámetros mejor).
Por último, ponemos un nombre a la imagen con -o y con -p escribimos el prompt de la imagen. Al contrario que otros modelos que consumen más, los modelos de SDXL funcionan con un CLIP que se basa en prompts de palabras clave separadas, por lo que el prompt tendrá que ser una lista de conceptos clave, ordenados de más importante a menos.
Al ejecutar el script, a los pocos segundos obtendremos una imagen generada:

Ahora que sabemos lo básico para generar una imagen, tenemos que aprender sus detalles. Vamos a lanzar sd-server en lugar de sd-cli, ya que este servidor, además de proporcionarnos una API para consumir, nos ofrece una interfaz gráfica similar a ChatGPT para generar las imágenes más cómodamente:
sd-server -m juggernautXL_ragnarokBy.safetensors -W 800 -H 600 --listen-port 8998
Después de cargar el modelo y entre los mensajes que nos devuelve, podemos acceder a la URL http://localhost:8998. No tiene tantas opciones de personalización como el cliente de terminal, pero es una interfaz suficiente para hacer pruebas y generar de forma cómoda nuestras imágenes. Recuerda que para utilizarlo desde otro equipo de la red o desde WSL tendrás que indicar también el parámetro --listen-ip 0.0.0.0.
5. Optimización
Vamos con algunos consejos de optimización a la hora de utilizar sd.cpp. Entiende que estos consejos dependen mucho de los recursos de cada usuario. Lo ideal es entender bien como funcionan, y decidir cuando aplicarlos o no:
| Parámetro | Explicación |
|---|---|
--fa |
✅ Optimiza el uso de VRAM del modelo, CLIP y VAE para acelerar. Sólo si tienes mucha VRAM. |
--diffusion-fa |
✅ Optimiza el uso de VRAM del modelo y acelera cálculo en GPUs modernas. |
--vae-tiling |
✅ Procesa el VAE por fragmentos. Útil en resoluciones mayores a 1024x1024. |
--rng cuda |
✅ Genera números aleatorios con GPU. Usa --rng cpu si estás falto de VRAM. |
--t 8 |
✅ Indica el número de hilos de CPU a usar: 8, 16, ... |
--clip-on-cpu |
❌ Mueve el CLIP a CPU para ahorrar VRAM. Aconsejable en SDXL. |
--vae-on-cpu |
❌ Mueve el VAE a CPU para ahorrar VRAM. Sólo si no hay más remedio. |
--offload-to-cpu |
❌ Mueve el modelo a CPU hasta que lo necesita en VRAM. Sólo si no hay más remedio. |
6. Generación
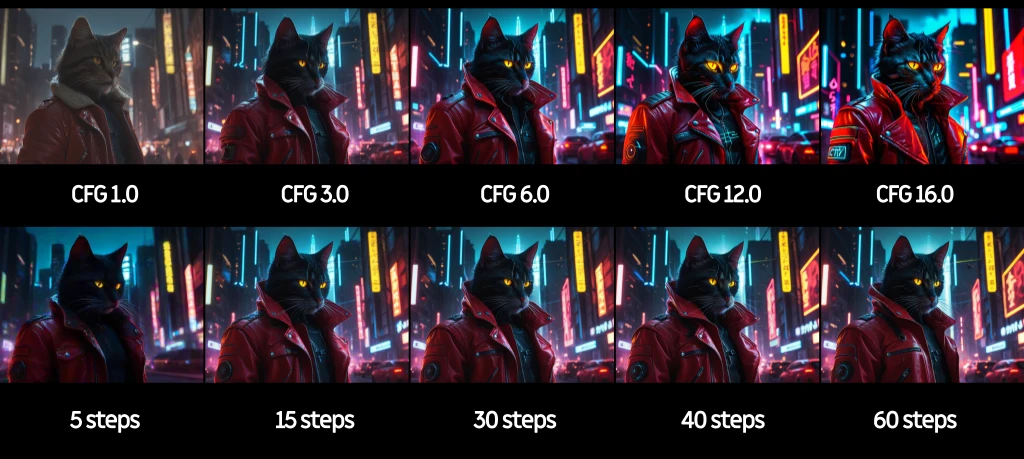
Vamos a profundizar un poco en la generación de imágenes. Hay 4 valores importantísimos cuando generamos imágenes con Stable Diffusion: escala CFG, número de pasos, método de sampling y scheduler.
-
CFG: Es la fidelidad al prompt. A valores más bajos, menos fiel al prompt (más libre y creativo), a valores más altos, más fiel al prompt (pero colores quemados o resultado muy artificial). Un buen valor para primeras pruebas podría ser
2.0o3.0. -
Steps: Son los pasos de refinado o iteraciones. Es el número de veces que la IA va limpiando el ruido. Con valores bajos, generación rápida pero borrosa o incompleta. Con valores altos, imagen más definida, pero tarda más y a partir de cierto punto no realiza cambios. Un buen valor para empezar podría ser
20 steps.
sd-cli --cfg-scale 7.0 --steps 20 ...
- Método de sampling: Método de muestreo. Es el algoritmo utilizado para generar la imagen. Puedes utilizar
EuleroEuler Ancestralpara empezar.
sd-cli --sampling-method euler_a ...

- Scheduler: Es el programador de ruido. Va muy de la mano con el método de sampling y decide en que momento reparte el ruido durante los pasos de generación. Puedes utilizar
simpleokarraspara empezar.
sd-cli --scheduler simple ...

Prueba con los diferentes valores y experimenta. Todo esto depende del prompt y los demás valores, así como de la imagen que quieras generar.